Implémentation technique GEO : Guide Complet 2026

Votre contenu est optimisé pour Google, mais invisible dans ChatGPT, Perplexity ou Gemini ? Ce n'est pas un bug — c'est un signal que votre implémentation technique GEO n'existe tout simplement pas. Alors que 65% des recherches B2B en 2026 passent par des interfaces conversationnelles, les marques qui négligent l'optimisation générative s'exposent à une obsolescence numérique brutale. Ce guide transforme votre infrastructure technique en machine de visibilité IA-native.
Ce que vous allez maîtriser : l'architecture data sous-jacente au GEO, l'intégration de schema.org avancé, la gestion des entités nommées, la latence critique des réponses génératives, et les métriques de succès spécifiques aux moteurs de recherche génératifs. Chaque section délivre des implémentations concrètes, testées sur des environnements de production à fort trafic.
Prérequis : Auditer votre maturité technique GEO
Avant d'injecter du code, établissez un diagnostic factuel de votre positionnement actuel. L'implémentation technique GEO n'est pas une couche cosmétique — elle repose sur des fondations solides que la majorité des sites négligent systématiquement. Voici votre checklist d'évaluation préalable, structurée autour de cinq piliers non négociables.
- Crawlabilité par agents IA : Vos pages se chargent-elles en moins de 2 secondes sans JavaScript exécuté ? Les moteurs génératifs privilégient le contenu statiquement disponible.
- Structuration sémantique native : Chaque page clé dispose-t-elle d'un objet JSON-LD complet avec au minimum 5 propriétés schema.org pertinentes ?
- Résolution d'entités : Votre contenu mentionne-t-il des entités nommées (personnes, organisations, lieux, produits) liées à des identifiants uniques (Wikidata, Google Knowledge Graph) ?
- Traçabilité des sources : Proposez-vous des citations vérifiables, des liens permanents vers vos données brutes, ou des identifiants DOI pour vos recherches propriétaires ?
- Gouvernance du changement : Votre équipe dispose-t-elle d'un processus documenté pour valider l'impact GEO de chaque modification de structure de données ?
L'erreur fondamentale consiste à traiter le GEO comme du SEO amélioré. C'est une discipline architecturale distincte. Où le SEO optimise pour l'indexation, le GEO optimise pour la synthèse — et ces deux objectifs entrent fréquemment en tension technique.
Si vous validez moins de trois critères sur cinq, suspendez immédiatement toute production de contenu et concentrez vos ressources sur la reconstruction de ces fondations. L'audit technique SEO reste le point de départ incontournable, mais il doit être étendu spécifiquement aux exigences des modèles de langage. Pour les équipes Genevoises, notre accompagnement technique GEO intègre cette maturité dans un diagnostic préalable systématique.
Étape 1 : Architecturer votre infrastructure data pour la synthèse IA
Les moteurs de recherche génératifs ne consultent pas votre site comme un utilisateur humain. Ils ingèrent des corpus textuels prétraités, structurés en embeddings vectoriels, puis interrogés via des mécanismes de retrieval-augmented generation (RAG). Votre implémentation technique GEO commence donc par la conception d'une architecture data que ces systèmes peuvent décomposer, contextualiser et reconstituer fidèlement.
Modulariser votre contenu en unités sémantiques indépendantes
La fragmentation est votre alliée. Au lieu de publier des articles monolithiques de 3000 mots, structurez votre savoir en modules thématiques de 150-400 mots, chacun centré sur une intention de recherche unique. Chaque module doit être compréhensible isolément tout en maintenant des liens contextuels vers des modules parent et enfants. Cette granularité permet aux systèmes RAG d'extraire précisément le segment pertinent sans dilution sémantique.
Implémentez cette modularisation via des composants réutilisables dans votre CMS headless. Payload CMS offre une structure de collections particulièrement adaptée à cette décomposition atomique. Chaque collection représente un type d'entité — service, étude de cas, FAQ, définition technique — avec des relations explicites codées en base de données plutôt qu'inférées par proximité textuelle.
Construire des graphes de connaissances internes navigables
Au-delà de la modularisation, établissez des graphes de relations entre vos entités. Quand un module mentionne l'implémentation technique GEO, il doit pointer vers des nœuds connexes : SEO technique, optimisation LLM, structured data, ou études de cas sectorielles. Ces arêtes du graphe sont codées explicitement dans vos métadonnées, pas seulement suggérées par la navigation visuelle.
Pour les implémenter, utilisez les propriétés schema.org `isRelatedTo`, `about`, `mentions` et `subjectOf`. Déclarez également des relations inverses — si le module A référence B, B doit référencer A via `citation` ou `isBasedOn`. Cette bidirectionnalité renforce la confiance des systèmes de synthèse dans l'autorité et la cohérence de votre corpus.
Un graphe de connaissances mal construit est pire que l'absence de graphe. Les hallucinations des LLM amplifient les incohérences structurelles. Validez chaque relation par un processus éditorial avant sa publication technique.
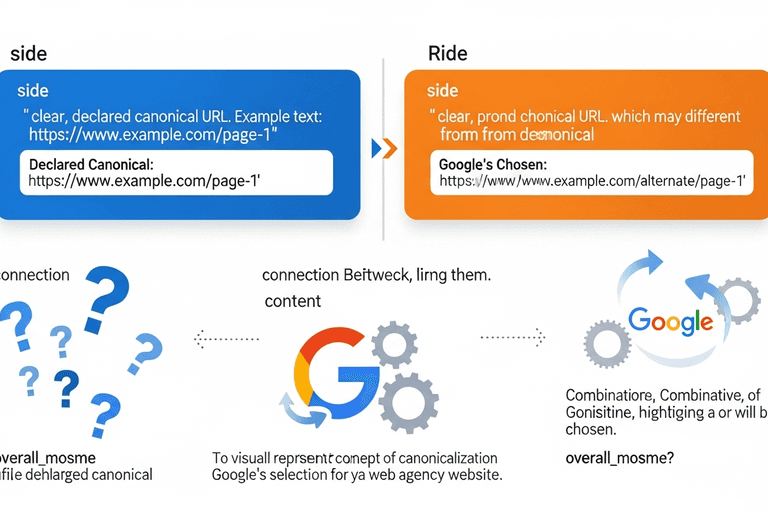
Étape 2 : Implémenter le JSON-LD avancé pour le GEO
Le JSON-LD n'est plus un bonus SEO — c'est le protocole de traduction entre votre contenu humain-readable et les embeddings compréhensibles par les modèles de langage. Une implémentation technique GEO robuste exige que chaque page stratégique embarque un objet JSON-LD valide, enrichi de propriétés qui aident spécifiquement à la synthèse générative.
Structurer les propriétés critiques pour la synthèse IA
Au-delà des basiques `name`, `description` et `url`, intégrez systématiquement ces propriétés schema.org sous-exploitées : `abstract` pour un résumé exécutif de 50 mots maximum, `about` pointant vers une entité Wikidata définie, `audience` qualifiant le segment cible avec `Audience` schema, `dateModified` fraîchement maintenu, `author` avec `Person` ou `Organization` et identifiant ORCID pour les individus, `citation` vers vos sources primaires, et `learningResourceType` quand applicable.
Pour une page de service comme notre offre développement sur mesure Genève, le JSON-LD pourrait inclure `areaServed` avec un `Place` référençant Wikidata Q71 (Genève), `provider` avec notre organisation et son numémo SIRET, `serviceType` lié à un vocabulaire contrôlé, et `hasOfferCatalog` détaillant les prestations spécifiques. Cette richesse sémantique permet aux LLM de vous positionner avec précision dans des réponses comme « Quelle agence web à Genève propose du développement Node.js certifié ? »
Valider et monitorer l'intégrité structurelle
Un JSON-LD invalide est toxique pour le GEO. Il crée de la confusion sémantique que les modèles de langage traduisent en exclusion. Automatisez la validation via des tests unitaires dans votre pipeline CI/CD — chaque déploiement doit vérifier la conformité schema.org, la résolution des URLs internes, la cohérence des types d'entité, et l'absence de propriétés requises manquantes.
- Utilisez le Schema Markup Validator de Google pour la validation initiale, mais ne vous y limitez pas — il ne couvre pas les exigences GEO-spécifiques.
- Implémentez des tests personnalisés avec jsonschema Python ou Ajv en JavaScript pour valider vos extensions propriétaires.
- Monitorer la fraîcheur via un tableau de bord technique : alerte si `dateModified` dépasse 90 jours sur une page stratégique.
- Versionnez vos schémas — les évolutions de schema.org peuvent invalider des structures précédemment conformes.
Étape 3 : Optimiser la latence et l'accessibilité machine
Les moteurs de recherche génératifs opèrent sous des contraintes de coût computationnel strictes. Si votre contenu exige plus de tokens de contexte pour être compris, ou si sa récupération nécessite des chaînages de requêtes complexes, il sera systématiquement sous-échantillonné ou ignoré. L'implémentation technique GEO exige une optimisation drastique de la latence perçue par les systèmes automatisés.
Maîtriser le First Contentful Paint pour crawlers IA
Contrairement aux navigateurs utilisateurs, les crawlers IA ne patientent pas. Les systèmes de retrieval ont des timeouts agressifs, souvent sous 3 secondes pour l'ensemble de la chaîne de récupération. Votre contenu critique doit être servi en moins de 800ms TTFB (Time To First Byte), avec le contenu textuel significatif disponible dans les premiers 14 Ko transférés — la taille typique d'une fenêtre TCP initiale.
Cette exigence invalide de nombreuses architectures modernes. Un site WordPress traditionnel avec 15 plugins actifs dépasse rarement ce seuil. La migration WordPress vers Next.js élimine cette friction par le pré-rendering statique et le streaming progressif. Pour les équipes évaluant cette transition, notre comparatif Next.js vs WordPress détaille les gains de performance mesurables.
Garantir la lisibilité sans exécution JavaScript
Les systèmes de retrieval exploitent massivement le rendu statique. Si votre contenu principal nécessite l'exécution de React, Vue ou Angular pour devenir visible, une portion significative de votre audience machine ne l'atteindra jamais. Implémentez le Server-Side Rendering (SSR) ou le Static Site Generation (SSG) pour tout contenu stratégique. Le contenu dynamique client-side doit être limité aux interactions post-chargement, jamais à la découverte initiale d'information.
Testez systématiquement avec curl : `curl -A "Mozilla/5.0 (compatible; GPTBot/1.0)" https://votresite.com/page`. Si le contenu textuel significatif n'apparaît pas dans les 50 premières lignes de réponse, votre implémentation technique GEO est compromise.
Étape 4 : Gérer les entités nommées et la résolution d'identité
Les modèles de langage ne raisonnent pas sur des chaînes de caractères — ils raisonnent sur des entités. Quand vous mentionnez « Genève », le LLM ne manipule pas le mot mais le concept Q71 de Wikidata, enrichi de toutes ses propriétés géographiques, historiques et économiques. Votre implémentation technique GEO doit faciliter cette résolution d'entité à chaque occurrence significative.
Annoter les entités avec des identifiants pérennes
Pour chaque entité nommée de votre contenu, déterminez si un identifiant d'autorité existe : Wikidata pour les concepts généraux, ORCID pour les chercheurs, ROR pour les institutions, ISNI pour les créateurs, DOI pour les publications scientifiques. Intégrez ces identifiants dans votre JSON-LD via `sameAs` ou `identifier`, et mentionnez-les textuellement quand cela sert la clarté humaine.
Imaginons une étude de cas sur notre agence web Genève. Au lieu d'écrire « basée à Genève », structurez : « Studio Dahu, agence de création de sites internet à Genève, située dans le canton homonyme (Wikidata Q71) ». Cette triple ancre — texte descriptif, lien interne sémantique, identifiant d'autorité — maximise les chances de résolution correcte par les systèmes de knowledge extraction.
Désambiguïser les entités polysémiques
Java (langage) vs Java (île), Apple (entreprise) vs apple (fruit) — les ambiguïtés détruisent la précision des réponses génératives. Quand votre contenu touche une entité polysémique, employez des marqueurs de désambiguïsation explicites : appositions descriptives, liens vers la page d'autorité pertinente, ou utilisation de la propriété schema.org `disambiguatingDescription`.
- Première mention : utiliser la forme complète désambiguïsée (« le framework Java Spring » plutôt que « Java » isolé).
- Mentions suivantes : maintenir le contexte dans la même section sémantique.
- JSON-LD : lier explicitement via `about` vers l'entité correcte, jamais laisser l'inférence au hasard du modèle.
- Éviter les pronoms ambigus dans les paragraphes denses en entités — préférer la répétition ou les synonymes explicites.
Étape 5 : Sécuriser la traçabilité et la vérifiabilité des sources
Les moteurs de recherche génératifs sont sous pression réglementaire et utilisateur pour citer leurs sources. Les modèles qui peuvent attribuer une information à une source vérifiable avec confiance élevée vont privilégier cette information. Votre implémentation technique GEO doit transformer chaque assertion significative en point d'ancrage vérifiable.
Structurer les citations et références
Chaque chiffre, statistique, citation directe ou conclusion analytique doit être accompagnée d'une référence structurée. Utilisez la propriété `citation` de schema.org avec des objets `CreativeWork` détaillant l'URL permanente, l'auteur, la date de publication et le titre. Pour les données propriétaires, publiez un document méthodologique accessible et référencez-le systématiquement.
Cette traçabilité s'applique également aux contenus génératifs. Si vous utilisez des outils IA pour produire des analyses, documentez le pipeline : modèle utilisé, version, date d'inférence, et toute post-édition humaine. Notre politique de confidentialité Big Brain AI et nos conditions d'utilisation encadrent cette transparence pour l'ensemble de nos productions assistées.
Maintenir des archives immuables pour la reproductibilité
Les URLs meurent, les contenus migrent, les entreprises disparaissent. Pour que vos citations restent vérifiables dans le temps, archivez vos sources primaires via des services d'archivage web ou publiez des versions statiques immuables. Référencez ensuite l'identifiant d'archive dans votre propriété `citation` via `archivedAt`.
Une source non vérifiable est une source non citée par les LLM. Le coût de vérification d'une information — temps de résolution d'URL, incertitude sur la fraîcheur, ambiguïté de l'attribution — pousse les systèmes de génération à l'ignorer au profit d'alternatives mieux structurées.
Étape 6 : Implémenter la fraîcheur et la mise à jour continue
Les modèles de langage valorisent énormément la temporalité. Une information de 2024 sur un sujet évolutif comme l'implémentation technique GEO vaut intrinsèquement moins qu'une information de 2026, même si le contenu ancien est techniquement correct. Votre infrastructure doit supporter la mise à jour continue sans friction technique.
Automatiser les cycles de révision par date d'obsolescence
Définissez des durées de validité par type de contenu : 90 jours pour les sujets technologiques rapides, 12 mois pour les analyses sectorielles, 24 mois pour les guides méthodologiques fondamentaux. À l'échéance, déclenchez automatiquement un workflow de révision éditoriale et technique. Mettez à jour `dateModified`, versionnez le contenu si la structure change significativement, et publiez un changelog visible.
Cette fraîcheur technique se manifeste dans votre JSON-LD via `dateModified` actualisé, `version` incrémentée, et potentiellement `archivedAt` pointant vers la version précédente. Les systèmes de retrieval détectent ces signaux de maintenance active et augmentent la pondération de votre contenu dans les réponses génératives.
Signaler les mises à jour majeures aux systèmes externes
Ne comptez pas sur le crawling passif pour propager vos mises à jour. Utilisez les sitemaps XML avec `lastmod` précis, les pings d'indexation vers les moteurs majeurs, et pour les contenus critiques, des notifications explicites via les API de soumission disponibles. Pour les connaissances structurées, envisagez la publication sur Wikidata ou des répertoires sectoriels référencés par les LLM.
Étape 7 : Mesurer l'impact et itérer stratégiquement
Sans métriques, l'implémentation technique GEO est de l'artisanat aveugle. Établissez un tableau de bord spécifique qui isole les indicateurs de visibilité générative des indicateurs SEO traditionnels. Ces deux univers se chevauchent mais ne se superposent pas — une page bien classée sur Google peut être invisible dans Perplexity, et inversement.
Définir les KPIs GEO natifs
Les métriques pertinentes incluent : la fréquence de citation de votre marque dans les réponses génératives pour vos requêtes cibles, le taux d'attribution correcte (votre contenu est-il cité comme source ?), la précision sémantique (les réponses reflètent-elles votre positionnement ?), et la couverture thématique (quelle proportion de vos sujets stratégiques apparaît dans les synthèses IA). Pour les équipes avancées, évaluez le coût de développement d'application mobile en Suisse 2025 comme benchmark de contenu technique fortement recherché.
Ces métriques nécessitent des outils de monitoring spécialisés. Des solutions émergentes comme Perplexity Pages, GigaBrain, ou des scrapers dédiés couplés à l'évaluation LLM permettent d'automatiser cette collecte. Pour un démarrage manuel, constituez une liste de 50 requêtes représentatives et auditez mensuellement les réponses des principales interfaces conversationnelles.
Institutionnaliser l'amélioration continue
Le GEO n'est pas un projet ponctuel. Les modèles de langage évoluent mensuellement, les comportements de recherche se transforment, et la compétition s'intensifie. Établissez un rituel d'examen trimestriel : révision des entités cibles, actualisation des schémas JSON-LD, benchmark contre les leaders de visibilité générative, et ajustement de la stratégie de contenu modulaire. Cette discipline d'amélioration continue distingue les implémentations qui survivent des celles qui dominent.
- Mois 1 : Audit complet, établissement de la baseline, priorisation des quick wins.
- Mois 2-3 : Implémentation des fondations (architecture, JSON-LD, entités), première mesure d'impact.
- Mois 4-6 : Itération sur la modularisation, expansion thématique, optimisation de la latence.
- Mois 7-12 : Industrialisation, automatisation des mises à jour, veille concurrentielle systématisée.
Récapitulatif et checklist d'implémentation
Avant de conclure, consolidons l'ensemble des exigences techniques en une checklist actionnable que votre équipe peut utiliser immédiatement pour valider l'état de votre implémentation technique GEO ou guider sa construction.
- Architecture data modulaire avec relations explicites entre entités de type différent.
- JSON-LD valide sur 100% des pages stratégiques, avec propriétés GEO-spécifiques (`abstract`, `about`, `audience`, `citation`).
- Latence < 800ms TTFB, contenu textuel significatif dans les 14 Ko initiaux.
- Rendu serveur ou statique pour tout contenu de découverte ; JavaScript client réservé aux interactions.
- Entités nommées annotées avec identifiants d'autorité (Wikidata, ORCID, ROR) et désambiguïsées.
- Sources traçables via `citation` structurée, archives immuables pour les références critiques.
- Processus de fraîcheur automatisé avec `dateModified` actualisé et versioning des évolutions majeures.
- Tableau de bord GEO distinct du SEO, avec KPIs natifs et cycle d'amélioration trimestriel.
Cette checklist n'est pas une fin en soi — c'est le socle minimal. Les organisations qui dominent le GEO en 2026 l'ont déjà dépassée pour intégrer des stratégies de données structurées pour agents IA et des workflows d'automatisation conversationnelle.
Prochaines étapes pour dominer le GEO
L'implémentation technique GEO que vous avez découverte ici transforme votre infrastructure numérique en actif stratégique durable. Mais la technologie seule ne suffit pas — elle doit s'accompagner d'une stratégie de contenu éditorial calibrée pour la synthèse IA, d'une gouvernance des données enterprise-grade, et d'une culture d'expérimentation continue.
Pour les organisations genevoises et suisses romandes qui souhaitent accélérer cette transformation sans mobiliser 18 mois de recrutement interne, Studio Dahu propose un accompagnement intégré. De l'audit technique initial à l'industrialisation de votre présence IA-native, nous architecturons chaque couche de votre visibilité générative avec la rigueur technique et la créativité stratégique qui fondent notre réputation depuis 2019. Estimez votre projet dès maintenant et positionnez-vous pour l'ère de la recherche conversationnelle.
Questions fréquentes
Quelle différence fondamentale entre l'implémentation technique GEO et le SEO traditionnel ?
Le SEO optimise pour l'indexation et le classement dans des pages de résultats. Le GEO optimise pour la synthèse — la capacité d'un modèle de langage à extraire, recombiner et attribuer votre contenu dans des réponses génératives uniques. Cela exige une architecture data radicalement différente, centrée sur la modularité sémantique et la traçabilité des sources.
Combien de temps faut-il pour observer des résultats mesurables en GEO ?
Les fondations techniques (JSON-LD, latence, entités) produisent des effets détectables en 4 à 8 semaines. Les gains de visibilité générative significatifs émergent généralement après 3 à 6 mois de production modulaire continue, le temps que les corpus de training des LLM intègrent vos nouvelles structures de données.
Le GEO remplace-t-il le SEO ou les complète-t-il ?
Le GEO complète et étend le SEO. Les moteurs de recherche classiques restent dominants pour le trafic transactionnel direct. Le GEO capture les recherches exploratoires, complexes et conversationnelles qui échappent au modèle keyword-page. Les deux disciplines partagent des fondations techniques (crawlabilité, structured data) mais divergent sur l'optimisation sémantique profonde.
Quel CMS recommandez-vous pour une implémentation technique GEO robuste ?
Les CMS headless avec structure de contenu fortement typée sont idéaux. Payload CMS offre une flexibilité exceptionnelle pour la modélisation d'entités et de relations. Next.js comme couche de présentation garantit les performances et le rendu statique requis. Évitez les CMS monolithiques traditionnels dont la structure rigide contraint la modularisation sémantique.
Comment vérifier que mes pages sont effectivement exploitables par les crawlers IA ?
Testez avec curl en simulant les user-agents des crawlers IA (GPTBot, ClaudeBot, PerplexityBot). Vérifiez que le contenu textuel complet apparaît dans la réponse HTML brute, sans exécution JavaScript. Validez votre JSON-LD avec des outils spécialisés et auditéz la résolution de vos entités nommées via les APIs de Wikidata.